


In the world of programming, there are many concepts that every developer should understand in order to build efficient and reliable systems. One such vital concept is idempotency, which refers to the property of an operation or function that produces the same result when applied multiple times as it does when applied only once. This may seem like a simple concept, but it has significant implications for building distributed systems. In this article, we will explore what idempotency is, why it is important, and how to achieve it. Whether you are a beginner or an experienced developer, understanding idempotency is an essential skill that will help you build more robust and reliable systems.
Why Should Programmers Care About It?
Idempotency is a concept that is important for programmers to understand, especially those working on building distributed systems. In simple terms, idempotency means that if you perform an operation multiple times, the end result should be the same as if you had only performed it once.
In other words, an idempotent operation is one that can be repeated multiple times without causing any additional side effects. This is important in distributed systems because messages can sometimes be lost or duplicated due to network issues, and if an operation is not idempotent, repeating it can cause unintended consequences.
Let’s say you’re building an API for processing payments. If you design the API with idempotency in mind, you can ensure that even if the same payment request is sent multiple times due to network issues, it will only be processed once. This can prevent double-charging customers, which can lead to trust issues and lost revenue.
The “same” request hitting your API should not modify your state for the second time. (Milan Jovanović – Tweet)
A little more Idempotency APIs
We use many methods to design our systems to tolerate and reduce the probability of failure and avoid turning a small percentage of failures into a complete outage. Some of these are especially vital in distributed systems.
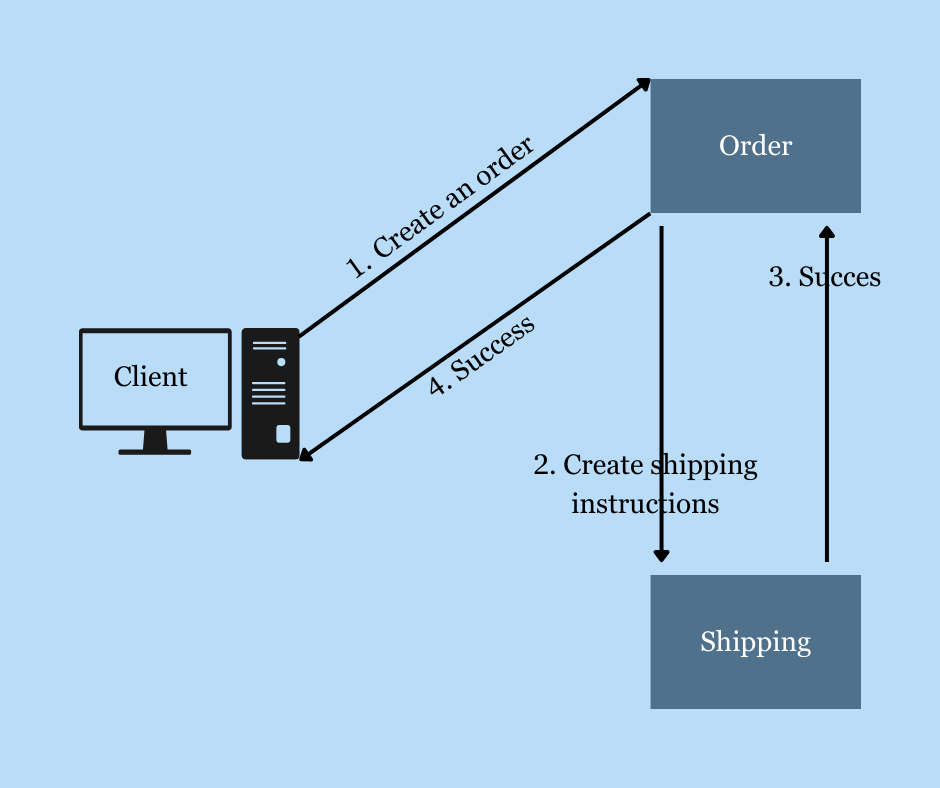
Let’s say we have a food ordering application, and to keep our application simple, let’s say we have two basic services, Shipping and Order. When one of our customers places an order, first the order is created, and then shipping instructions are created. If all transactions are successful, it sends a notification to the client. Even in this simple scenario, many failures can occur. These failures can come from a variety of factors. They include servers, networks, load balancers, software, operating systems, or even mistakes from system operators. For example, even if the order and shipping service do their job properly, what happens if the customer cannot receive a response due to network latency while returning the response? Of course, the first thing that comes to mind for such cases is to use patterns such as timeout, retry, and backoff. But what if we try the service call again in this scenario? Is it a situation that we want to re-order? Retrying the request can result in multiple orders with very serious consequences. That’s why it’s important to design Idempotent APIs.
Idempotency with HTTP Methods
HTTP (Hypertext Transfer Protocol) is a widely used protocol for communicating between web servers and clients. Idempotency plays an important role in the design of HTTP methods, which are used to define the type of action that a client wants to perform on a resource. In this section, we will explore how idempotency applies to some HTTP methods.
GETMethod:
The GET method is used to retrieve a resource from the server. It is an idempotent method because retrieving the same resource multiple times will not change the resource itself or cause any side effects on the server.PUTMethod:
The PUT method is used to update a resource on the server. It is idempotent because sending the same request multiple times will result in the same resource state as if the request had only been sent once. For example, if you send a PUT request to update a user’s email address with the same new email address multiple times, the user’s email address will only be updated once.DELETEMethod:
The DELETE method is used to delete a resource from the server. It is idempotent because deleting a resource multiple times will have the same result as deleting it only once. If the resource has already been deleted, sending a DELETE request for the same resource will not result in any changes.POSTMethod:
The POST method is used to create a new resource on the server or to submit data to be processed. It is not idempotent because sending the same request multiple times will create multiple resources or submit the same data multiple times, resulting in different outcomes.
And now a brief pause for a personal note
I want to make sure that my newsletter is meeting your needs and providing you with valuable content. That’s why I am taking a brief pause to ask for your input.
My next articles will be shaped according to your demands, so I want to hear from you! What topics would you like to see covered in future newsletters? Is there anything specific you’re struggling with that you’d like to see addressed in our content?
Simply reply to this email and let me know your thoughts. I value your feedback and look forward to incorporating your suggestions into our upcoming newsletters.
How to achieve idempotency in POST method?
In a distributed system with many clients making many calls and with many requests in flight, the challenge is how do we identify that a request is a repeat of some previous request?
Simply, it is possible to make a POST request idempotent by including a unique identifier in the request body or header, which can be used to identify and prevent duplicate requests.
Many approaches can be used to determine whether a request is a copy of an earlier request. For example, it may be possible to derive a synthetic token based on the parameters in the request. You can derive a hash of existing parameters and assume that any request with the same parameters from the same caller is a duplicate. On the surface, this seems to simplify both the customer experience and service implementation. Any request that looks exactly like a previous request is considered a duplicate request. However, this approach is unlikely to work in all situations. For example, let’s say you order a meal, and when your next-door neighbor orders the same meal, are these requests repeated or are they two different requests? Or after you place an order, your friend calls and says he’s hungry, and when you re-create the same order a short time later, will we treat them as renewed requests? Is this scenario very similar to the client retrying the service because of the network latency we just mentioned? It’s possible that the caller actually wants two identical meals.
The generally preferred approach is to include a unique caller-supplied client request identifier in the API contract. Requests from the same caller with the same customer request identifier can be considered duplicate requests and handled accordingly. A unique caller-supplied client request identifier for idempotent operations satisfies this need.
The following diagram shows a sample request/response flow that uses a unique client request identifier in an idempotent retry scenario:
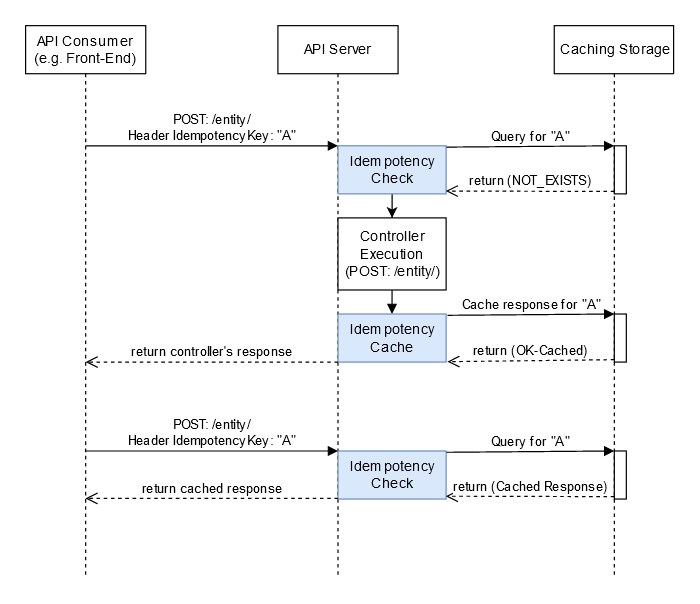
IdempotentAPI flow for two exact POST requests. In this example, a customer requests the creation of a resource that presents a unique client request identifier. On receiving the request, the service first checks to see if it has seen this identifier before. If it has not, it starts to process the request. It creates and stores an idempotent “session” for this request keyed off the customer identifier and their unique client request identifier. If a subsequent request is received from the same customer with the same unique client request identifier, then the service knows it has already seen this request and can take appropriate action.
There are two important points here. One is how long the unique customer request identifier will be stored and the other one is not successful if the transaction is not successful, the unique customer request identifier should not be created, that is, it should be an ACID transaction.
Conclusion
In this article, we have explored how idempotency applies to HTTP methods, which are a fundamental part of web development. We have seen that some HTTP methods, such as GET, PUT, and DELETE, are idempotent, while others, such as POST, are not. Knowing which methods are idempotent is crucial for building efficient and reliable systems.
Overall, understanding and implementing idempotency can help you build more robust and reliable systems, which is crucial in today’s world of distributed systems. Whether you are a beginner or an experienced developer, understanding idempotency is an essential skill that will help you build better software.
Thanks for reading! If you enjoyed this newsletter, please share it with your friends and/or subscribe!